
지난번에는 3개 이상 집단 간 평균의 차이를 검정하는 일원배치분산분석(one-way ANOVA)을 연습했다. 이번에는 통제변수가 추가된 분산분석, 즉 ‘공분산분석(영어 명칭은 ANCOVA)’을 해보고자 한다. 공분산분석은 분산분석(ANOVA)의 영어 명칭을 보면 알겠지만 ‘C’가 추가된 형태로, 여기서의 C는 ‘Covariance’, 즉 통제변수를 나타낸다고 보면 된다.
※ ANCOVA = ANOVA + Covariance(통제변수)
공분산분석(ANCOVA)은 분산분석(ANOVA)과 비교했을 때 해석을 하는 것에 있어서 큰 차이가 없으나, 분석 단계에서 통제변수가 추가되었기 때문에 조금 더 사실적이고 설득력 있는 결과를 제시할 수 있는 것이 특징이다. 특히 분석에 투입된 통제변수가 유의하다면 말이다.
분석에 앞서 예제파일을 살펴보자. 이름처럼 이 자료는 시간당 지급되는 임금에 관한 데이터이다.
파일을 열어보면 [agecat]는 연령 범주를 나타내는 것으로 세 개의 범주로 구성되어 있으며 일원배치분산분석뿐만 아니라 이를 응용한 형태인 공분산분석을 할 수 있는 조건을 갖추고 있다. [yrs] 역시 근속 연수를 나타내는 범주형 변수이다. 한편 [wage]는 근로자가 받는 시간당 급여고, [distance]는 출퇴근 거리를 나타내는 통제변수이다. 정리하면 [agecat]과 [yrs]는 3개 이상의 집단으로 구성된 명목척도이고, [wage]와 [distance]는 연속형 자료로 구성된 비율척도라는 것을 기억하고 다음으로 넘어가면 된다.
- [agecat], [yrs] : 명목척도(3집단 이상)
- [wage], [distance] : 비율척도
※ 기억하자! 공분산분석(ANCOVA)을 하기 위해서는 독립변수가 3개 이상의 집단(범주형)으로 구성된 명목척도여야 하며, 종속변수와 통제변수는 연속형으로 구성된 등간/비율척도여야 한다.
분석을 위해 다음과 같이 가설을 세웠다.
H1 : 출퇴근 거리[distance]를 통제한 상태에서 연령[agecat]에 지급되는 시간당 급여[wage]에는 유의한 차이가 있을 것이다.
이러한 형태의 가설은 매우 직관적으로 서술한 것이며, 실제로는 가설을 세울 때 가설1(H1)처럼 “특정 변수를 통제한 상태에서~” 식의 워딩을 넣는 경우가 많지 않다. 통제변수는 가설을 세울 때 언급을 하기보다는 분석 단계에서 투입하고 분석 결과를 해석할 때 중점을 두기 때문이다. 그래서 아래와 같이 가설을 세워도 무방하다.
H1 : 연령[agecat]에 따라 지급되는 시간당 급여[wage]에는 유의한 차이가 있을 것이다.
공분산분석(ANCOVA)을 하려면 통제변수를 투입하기 전 상태에서 일원배치분산분석을 통해 유의성을 검증하고 공분산분석을 진행하는 것이 바람직하다. 반드시 그런 건 아니지만 그 이유는 통제변수 투입 전/후를 비교하는 것에 초점을 두게될 수도 있기 때문이다. 일반적인 분산분석(즉, 통제변수를 투입하기 전) 방법은 지난번 포스팅 [SPSS#16] 일원배치분산분석(one-way ANOVA)을 참고하되, 분산의 동질성을 함께 검증하는 것도 잊지 말아야겠다(분산의 동질성은 p<0.05를 충족해야 함).
통제변수를 투입하기 전 상태에서 변수 간 평균의 차이가 유의한지 검증했다면 이제는 통제변수를 투입한 상태에서 공분산분석(ANCOVA)을 진행하면 된다. 방법은 다음과 같다. [분석(A) → 일반선형모형(G) → 일변량(U)]

앞서, 일원배치분산분석 포스팅에 따르면 연령[agecat]에 따라 지급되는 시간당 급여[wage]에는 통계적으로 유의한 차이가 있는 것으로 나타났다. 그런데 여기서 우리가 추가적으로 선택할 부분은 통제변수와 관련된 부분이다. 아래처럼 ‘종속변수’ 란에 시간당 급여[wage]를, ‘고정요인’ 란에 연령 범주[agecat]를, 그리고 ‘공변량(=통제변수)’에 출퇴근 거리[distance]를 넣어주자.
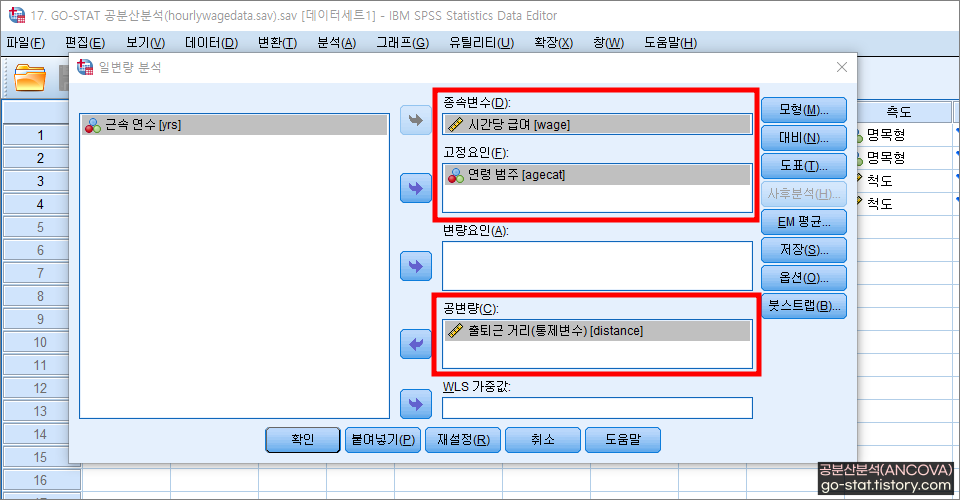
혹시 분산의 동질성 검정을 빠뜨렸다면 ‘옵션’을 눌러 ☑ 동질성 검정(H)에 체크해 주면 된다. ☑ 기술통계량(D)은 기본적으로 확인하는 부분이기에 같이 체크해 주었다.

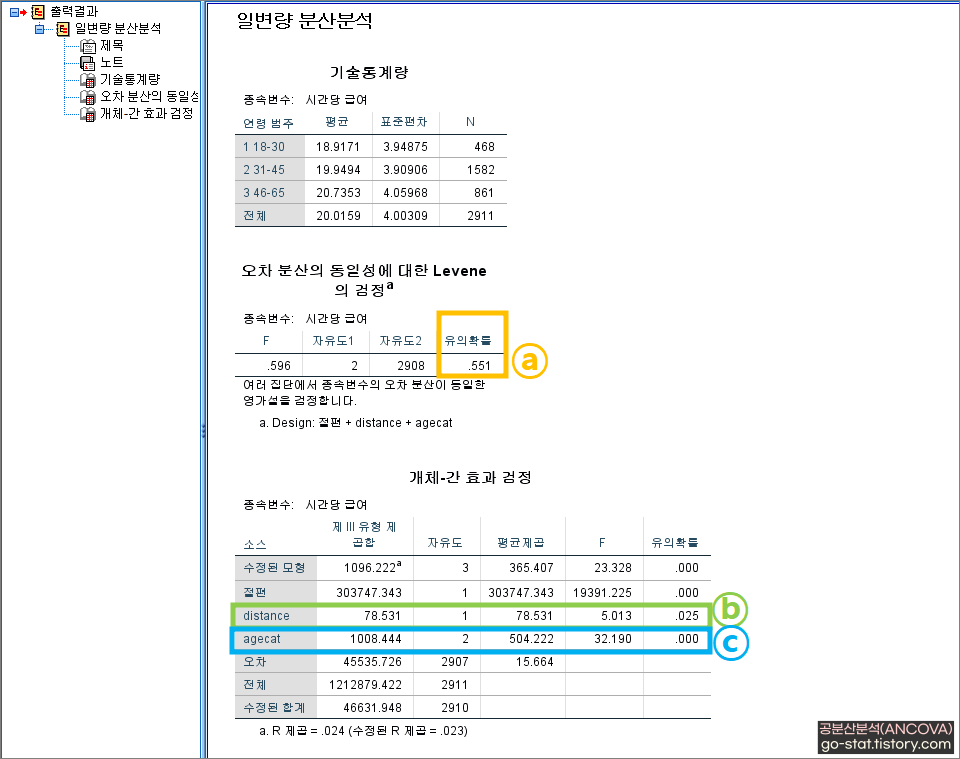
ⓐ 유의확률 이라고 나타난 부분은 분산의 동질성을 검증한 것으로 p값(유의확률로 표시된 부분)이 0.05보다 클 때 분산의 동질성이 충족된다(p>0.05). 이 경우, 0.551은 0.05보다 크므로 분산의 동질성이 충족되었다고 할 수 있다.
공분산분석은 결과 해석면에서 분산분석과 유사하다.
ⓑ는 통제변수에 대한 유의성을 나타낸다. 즉, ⓑ 출퇴근 거리[distance]의 p값이 0.025으로 p<0.05가 충족되어 결과에 영향을 미치는 유의한 통제변수임이 증명되었다. 사실 통제변수가 투입되었을 때 p값이 유의하던 유의하지 않던, 중요한 건 통제변수를 투입한 상태에서 고정요인(ⓒ 연령[agecat])이 유의했는가? 가 관점이다. 보다시피, ⓒ 연령[agecat]은 p<0.05가 충족되어 유의한 것으로 나타났다. 참고로 ⓒ 부분에서 p값이 0.000으로 나타나는 건 0이 아니라 0에 수렴할 정도로 매우 작은 숫자이기 때문에 이처럼 표시되는 것이다.
Q. 그렇다면 연구자는 이러한 결과를 어떻게 받아들여야 할까?
나라면 이렇게 이해하고 해석할 것이다. 통제변수인 출퇴근 거리[distance]의 영향력을 통제한 상태에서 연령[agecat]에 따른 시간당 급여[wage]에는 유의한 차이가 있었다. 그런데 도대체 왜? 통제변수를 투입했는데 오히려 통제변수의 영향력이 제거되었다고 설명할 수 있는 것일까? 나 역시도 궁금했지만 이렇게 생각하니까 이해하기 쉬웠다.
통제변수를 투입하는 건 결과에 대한 영향력의 일부를 통제변수가 가져가는 셈이 된다. 즉, 전체 영향력의 크기는 어느 정도 정해져 있는데 통제변수를 투입하면 기존의 독립변수가 종속변수에 미치는 영향력(또는 유의성)을 나눠가지는 것과 유사하다. 그래서 통제변수를 투입하면 결국 통제변수가 일정 부분만큼 영향력을 뺏어가기 때문에 이렇게 함으로써 통제변수를 제외하고 난 상태에서 순수한 유의성을 확인할 수 있는 것이다.
그러면 결과를 해석해 보자.
이러한 결과는 출퇴근 거리[distance]를 통제한 상태에서 연령[agecat]에 따라 지급되는 시간당 급여[wage]에는 유의한 차이가 있는 것으로 나타났다(F=32.190, p<0.001).
여기서 추가로 대소관계를 비교할 수 있는 사후검정도 진행하면 좋겠지만, 아쉽게도 SPSS 25.0 버전에는 공분산분석(ANCOVA)을 하면서 사후검정까지 같이 확인할 수 있는 기능이 안 보인다. 필요하다면 일반적인 분산분석 절차에서 사후검정을 진행할 수는 있겠으나, 공분산분석(ANCOVA)에서 사후검정까지 같이 진행하는 방법이 있는지는 추가적으로 검토해 보고 포스팅해야겠다.
그렇다면 이번 분석에서는 사용하지 않았지만, 근속 연수를 나타내는 변수 [yrs]를 이용하여 공분산분석(ANCOVA)을 해보는 것은 어떨까?