
요인분석은 타당도를 검증하기 위해 사용되는 주요 분석 방법 중 하나이다. 오늘 하려는 건 탐색적 요인분석(Exploratory Factor Analysis; EFA)이다. 요인분석은 크게 1) 탐색적 요인분석과 2) 확인적 요인분석으로 나뉠 수 있다. 이름에서 왜 탐색적 요인분석이라고 부르는지 궁금하다면, 요인분석을 해봐야지 만이 결과를 알 수 있기에.. 어떻게 요인이 묶일지는 분석하기 전에 미리 알기 어렵기 때문이라고 할 수 있다.
분석을 위해 어떤 데이터를 활용해 볼까..? 고민하던 중 ‘2018 외래관광객 실태조사 원자료(sav)’파일로 요인분석을 해보면 좋겠다는 생각이 들었다. 몇 년 지난 자료이지만 분석하는 데에는 이상이 없으므로 데이터 파일을 먼저 다운로드해 주자. 직접 사이트에서 다운로드하려면 아래의 링크를 클릭하면 된다.
접속 링크 : https://datalab.visitkorea.or.kr/site/portal/ex/bbs/View.do?cbIdx=1127&bcIdx=14675&pageIndex=1&tgtTypeCd=&searchKey=&searchKey2=&tabFlag=N&subFlag=Y&cateCont=spt05
파일을 열어보면 심상치 않다. 문항도 다양할 뿐만 아니라 방대한 자료가 들어있는 것을 알 수 있다.
나는 이 중에서 항목별 만족도에 대한 자료를 토대로 요인분석을 해보려고 한다.
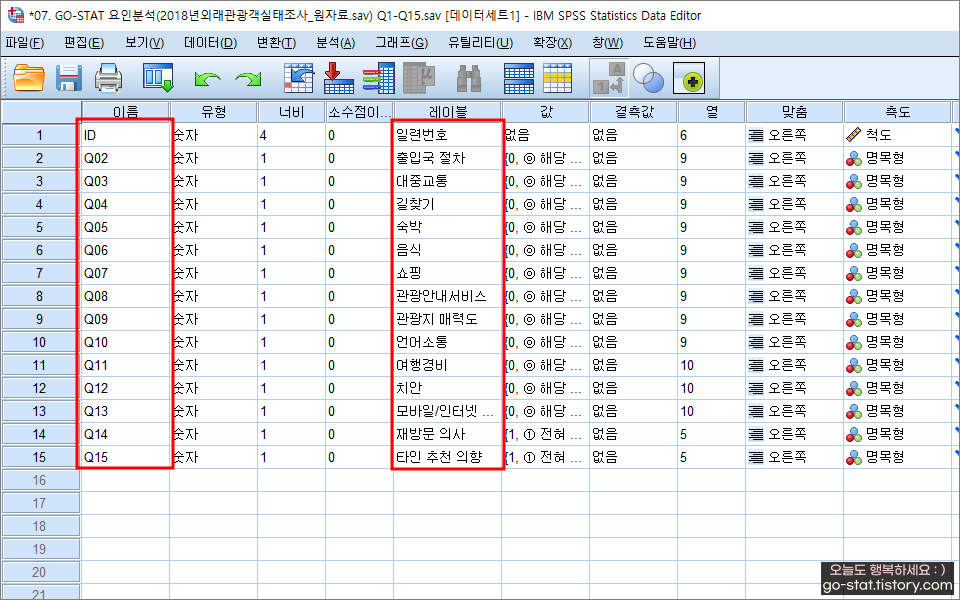
원본파일이 워낙 복잡해서 분석에 사용할 변수만 추려보았다. 아래의 사진은 분석에 활용할 변수들을 추린 모습이다. 이름을 편의상 Q02~Q15까지 바꿔주었고, 기존의 레이블도 설명이 다소 긴 듯하여 간단하게 요약해서 나타내주었다.
그런데 문제는 자료의 표본(n)이 무척 많다는거다. 물론 이 상태로 요인분석을 해도 되지만, 1% 정도에 해당하는 표본만 무작위 추출하여 요인분석을 해보면 좋겠다는 생각이 들어서 ‘케이스 선택’ 메뉴에 들어갔다. (요인분석에 필요한 절차는 아니지만, 경우에 따라서 무작위 선택을 해서 분석할 수 있다는 것을 보여주기 위함이며, 단순 예시이니 참고만 하길 바란다)
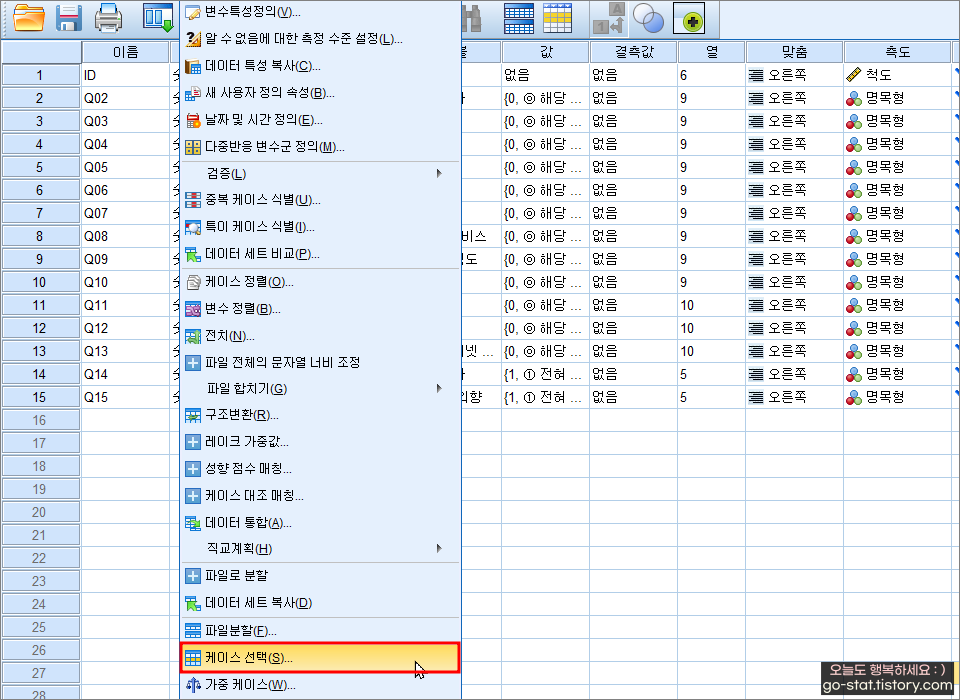
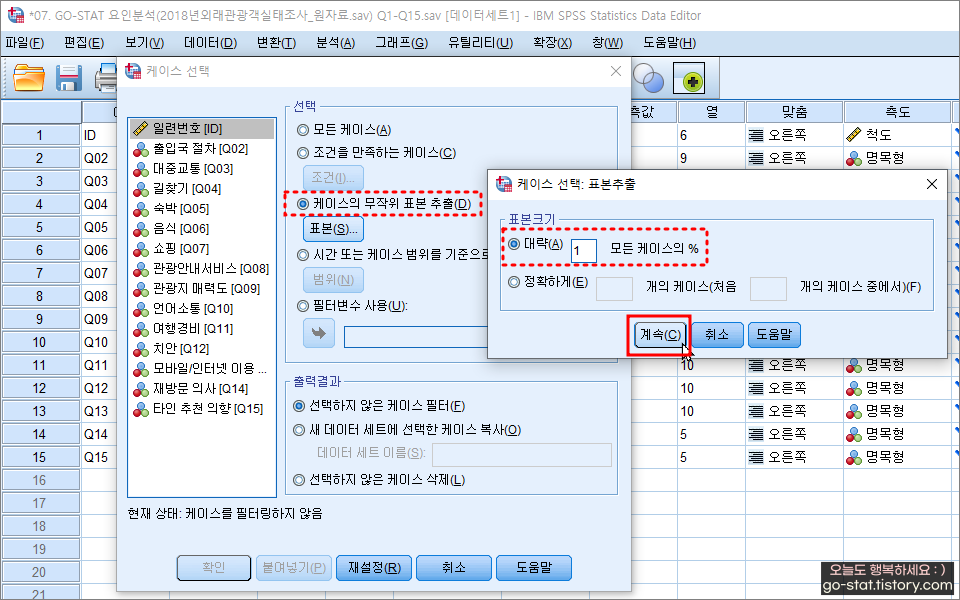
여기서 나는 전체 케이스의 1%만 무작위로 추출하고자 한다. 원래는 1만 개가 넘는 표본으로 구성되어 있는데, 여기서 1%에 해당하는 표본을 추출하니 160명 가량의 데이터가 추출되었다(물론 무작위 랜덤으로^^). 이는 무작위로 케이스를 추출하는 방식이기 때문에 케이스를 추출할 때마다 어떤 케이스가 추출될지 모르며, 이에 따른 요인분석 결과도 달라질 수 있음에 유의해야 한다.
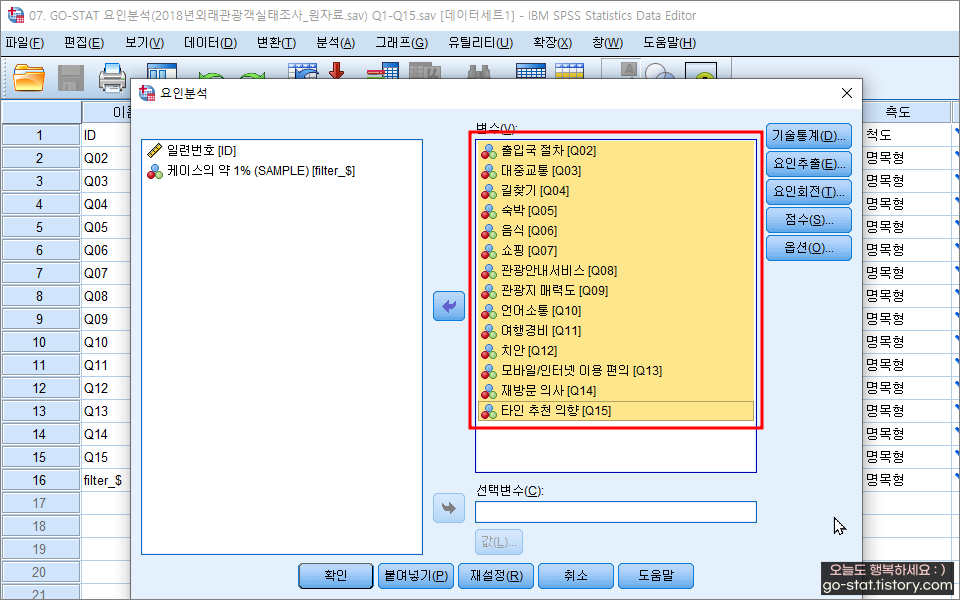
그럼 이제 요인분석을 해볼 차례~ 요인분석으로 들어가준다.

분석하고자 하는 대상을 ‘변수’ 칸에 넣어준다. 처음 시작은 모든 변수를 넣어줄 것.
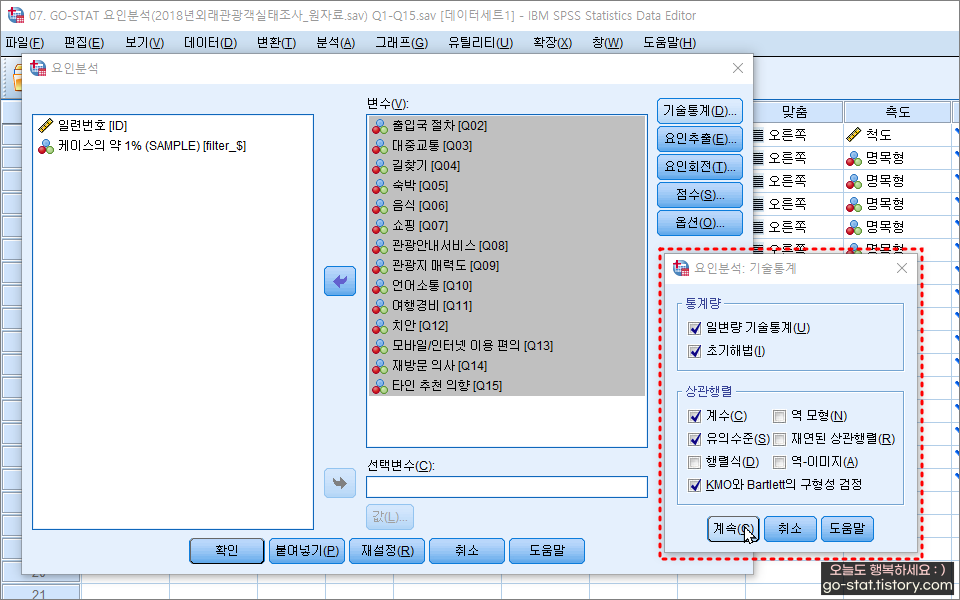
다음으로는 요인분석 결과를 확인하기 전에 몇 가지 설정을 해주어야 한다. ‘기술통계’를 눌러서 ☑일변량 기술통계, ☑계수, ☑유의 수준, ☑KMO와 Bartlett의 구형성 검정에 체크해 준다. 물론 여기에 있는 항목을 전부 다 체크해주어도 상관없다. 반드시 하나만 꼭 체크해야 한다면 ‘☑KMO와 Bartlett의 구형성 검정’이다.
다음으로는 ‘요인추출’을 선택해줄 차례이다. 나는 기본 방법인 ‘주성분’을 선택했다. 그러나, 분석 목적에 따라... 혹은 연구 목적에 따라서 요인추출 방법은 내 연구에 필요한 방법으로 적절하게 선택해주어야 한다. 다음으로는 ‘☑스크리 도표’에 체크를 하였으나 이는 참고적인 지표이므로 반드시 체크할 필요는 없다. 여기서는 ‘방법’이 무엇인지 확인해주고 계속을 눌러준다. 특별한 이유가 없다면 고유값 기준은 기본 설정인 ‘1’로 놔두는 것이 바람직하다.
다음으로는 ‘요인회전’을 설정할 차례이다. 요인회전을 어떤 방식으로 할 것인지 지정하지 않아도 되지만 내가 공부했던 쪽에서는 주로 베리멕스나 직접 오블리민을 많이 선택해서 분석하는 것을 볼 수 있었다. 그런데 이 역시도 정답은 없다. 남들이 한다고 해서 따라 하는 건 권장되지 않고, 내 연구에 적합한 방법을 찾아 요인회전 방식을 지정하면 된다. 다만, 요인회전을 하는 이유를 알고 지나가는 것이 좋겠다. 쉽게 말하면 요인회전 방식을 지정하는 이유는 우리 눈에는 보이지 않지만 어떻게 회전시켰을 때 도출되는 요인이 서로 상호독립적이면서 잘 나뉘는지 알게 해 줄 수 있기 때문에 요인을 회전시킨 상태에서 보는 것이라고 이해하면 된다. 눈에는 안 보이지만 요인을 잘 구별해주는 가상의 축이 있다고 생각하면 된다 : )
‘점수’ 탭에서는 크게 건드릴 부분이 없다. 일단 요인분석 결과를 보고 나중에 그 변수를 분석에 사용하고 싶을 때 ‘☑변수로 저장’을 체크하면 된다. 지금은 이 과정 없이 단순하게 분석 결과만을 확인하고자 한다.
이제 거의 다 왔다. 마지막으로 ‘옵션’을 지정할 차례이다. 선택사항이나 ‘☑크기순 정렬, ☑작은 계수 표시 안 함’에 체크를 해줄 것을 권한다. 작은 계수에 대한 기준은 연구자마다 다른데, 나는 보통 0.4로 지정하는 편이다. 즉, 0.4 보다 작으면 해당 요인에 속한다고 간주하지 않겠다는 의미이다.
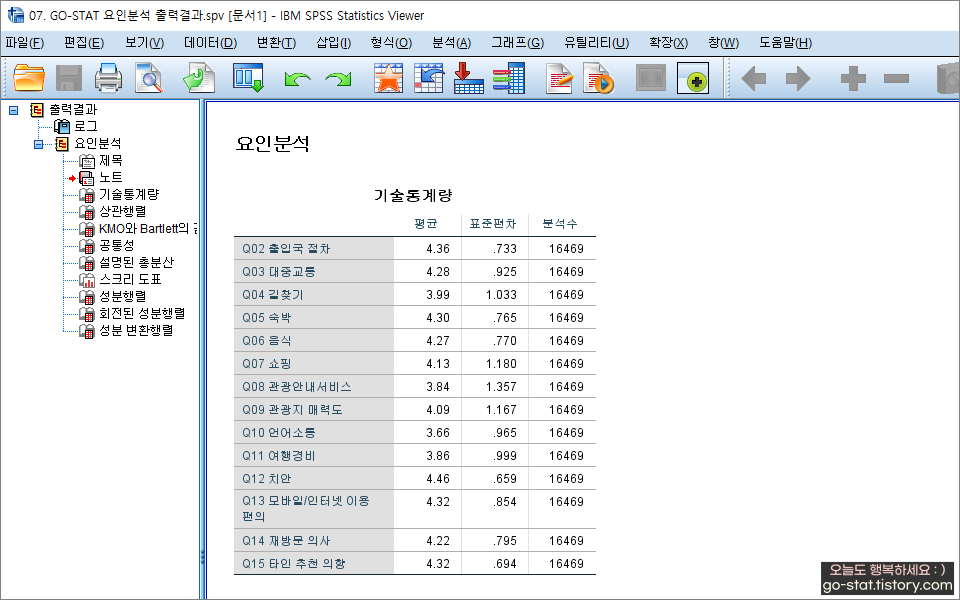
분석 결과를 확인해 보자. 가장 먼저 기술통계에 대한 분석결과가 도출된다. 여기서는 요인으로 묶이기 전의 각 변수에 대한 평균과 표준편차, 표본 수가 표시된다. 여기서 알게 된 거지만 아까 1%의 표본을 추출하겠다고 했는데, 파일을 닫고서 다시 열었더니 케이스 필터링이 되지 않은 상태에서 요인분석이 되었나 보다...ㅠㅠ 분석수(표본의 수 n=16.469) 그대로이기 때문이다. 뭐 아쉽지만 실습이니까 그대로 분석 결과를 해석해 봐야지!
문제는 표본의 수가 많아서 요인이 제대로 안 묶일 수도 있는데...ㅠㅠ 이런 상황을 감안해서 결과를 확인해보도록 하겠다.
다음으로는 상관행렬이 나온다. 이 부분은 연구나 논문에 크게 제시하지는 않는 부분이나, 각 변수 간의 상관관계와 유의확률(유의수준, p)을 알 수 있는 부분이다. 나는 이 부분을 논문에 제시하지 않고 참고만 한다.
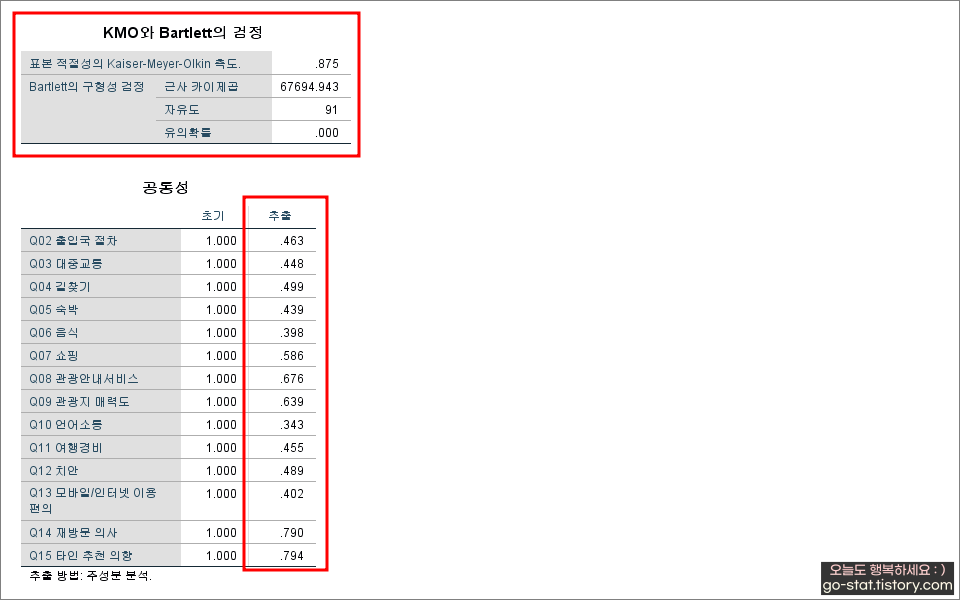
이제 나오게 될 부분, KMO와 Bartlett의 검정이 핵심적이다. 왜냐하면 요인분석에 대한 결과를 논문에 제시할 때 반드시 적어주어야 하는 부분이기 때문이다. KMO값과 Bartlett의 구형성검정에 대한 결과 값을 빼놓고 요인분석에 대한 결과표를 제시할 수 없다지 ^^. 다행히, KMO값은 0.6 이상으로 우수하며, Bartlett의 구형성 검정에 대한 결과 값도 p <0.001(넓은 관점에서 p <0.05를 충족함)로 유의한 것으로 확인되었다. 어느 정도의 KMO값이 대체 좋은 범위냐라고 묻는다면 그건 연구마다 다르다고 할 수 있다. 1에 가까울수록 높다고 보아야 하나, 0.7 이상만 되어도 무난하다.
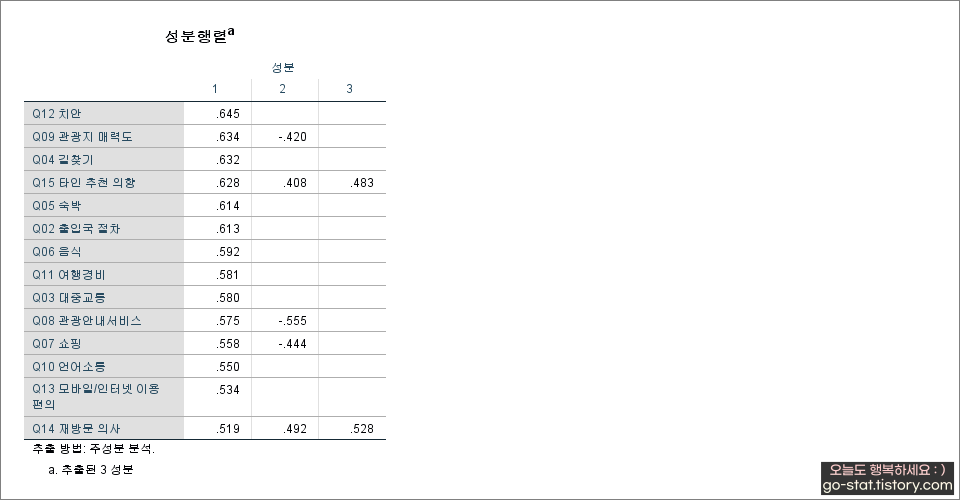
다음으로는 추출된 ‘공통성’ 값이다. 많은 연구에서 공통성이 0.4보다 작으면 요인분석에서 제거하는 편이 낫다고 말하는 경우가 있으나, 회전 요인행렬과 비교해서 제거할지 말지의 여부를 정하는 것이 좋겠다. 단순하게 수치가 낮다고 해서 문항을 제거해버리면 연구에 꼭 필요하지만 중요한 변수를 날려버리는 실수를 하게 될 수 있기 때문이다. 무조건 수치가 낮다고 해서 지우는 것은 아니니.. 공통성에서 추출된 값 중에서 유독 낮은 값이 있다면 주의 깊게 보되, 이 항목을 어떻게 처리할지는 연구자가 현명하게 생각해야 한다.
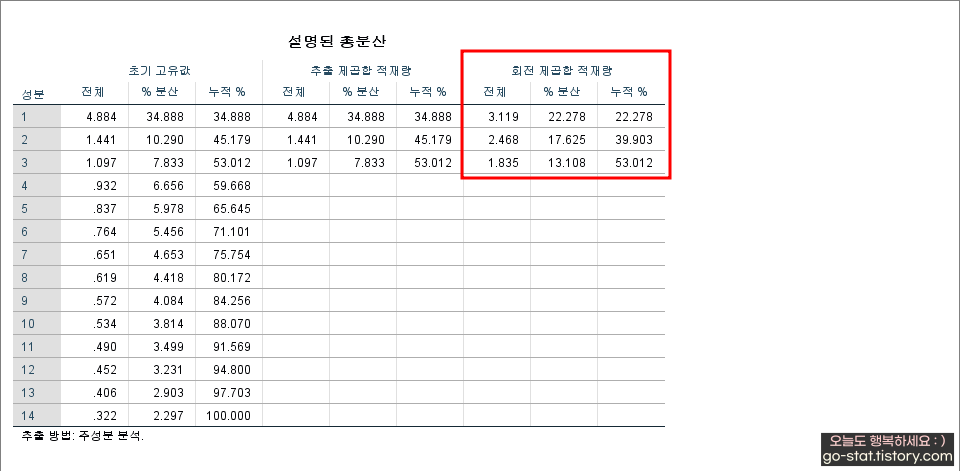
다음은 ‘회전 제곱합 적재량’이다. 총 3개의 요인으로 묶였으며 각 요인의 고유값을 확인하려면 ‘전체’ 아래에 표시된 값을 보면 된다. 이는 각 요인별로 설문 항목이 전체에서 얼마만큼의 비중을 차지하는지 볼 수 있는 부분이다. 즉, 요인분석으로 총 3개의 요인이 도출되었는데, 이 3개의 요인이 전체 14개의 문항(14개의 항목, Q2~Q15)을 얼마나 잘 구성하며 설명하는 것인지를 알 수 부분이다.
이때 연구자는 누적%(총 분산 설명력)도 함께 보아야 하는데, 아쉽지만 이 요인분석에서 총 분산설명력은 53.012%로 확인되었다. 즉, 요인분석의 결과로 이 3개의 요인이 14개의 항목을 53.012% 설명하는 것이다. 총 분산설명력(누적%)은 70% 이상이 되면 좋고, 60% 이상을 넘기는 것이 바람직하다. 아쉽지만, 이번 실습에서는 저조한 수치가 나왔다 ㅠㅠ 어떤 교수님은 총 분산설명력이 60%를 넘기지 못하면 실패한 요인분석이라고 말씀하기도 하는데.. 지금은 실습 중이니 약간 찝찝하더라도 일단 넘어가겠다. 하지만 실제 분석에서 총 분산설명력이 60%가 되지 않는다면 이대로 요인분석을 진행해도 괜찮을 것인가 신중하게 고민해보아야 한다.
다음은 스크리도표이다. 논문에 제시하지 않지만, 점을 기준으로 요인이 묶이고 있구나~ 하면서 참고용으로 확인하고 넘어간다.
요인분석의 결과로 3개 요인이 도출되었는데, 각각의 요인마다 속하는 항목이 무엇인지 알 수 있는 지표가 바로 ‘회전된 성분행렬’이다. 요인회전을 하는 이유가 바로 여기에 있다. 요인회전을 하기 전에는 어떤 항목들이 서로 요인으로 묶일지 모르지만, 회전방법을 지정해주면 보다 직관적으로 요인이 어떻게 묶이는지 확인할 수 있게 된다.
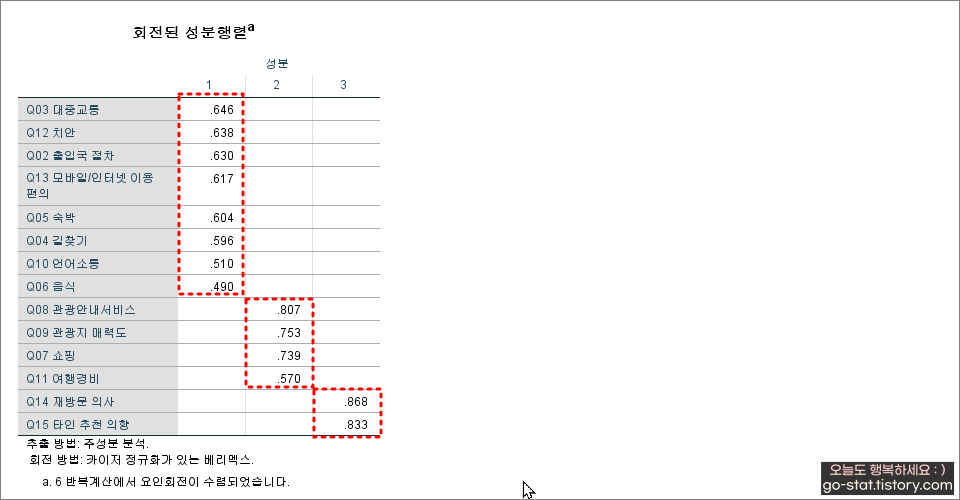
1번 요인에 ‘대중교통, 치안, 출입국 절차, 모바일/인터넷이용편의, 숙박, 길찾기, 언어소통, 음식’이 하나로 묶였다. 2번 요인에는 ‘관광안내서비스, 관광지 매력도, 쇼핑, 여행경비’가 묶였으며, 3번 요인에는 ‘재방문 의사, 타인 추천 의향’이 하나로 묶였다.
이제 연구자가 해야 할 일은 요인분석으로 나온 결과를 통해 요인명을 부여하는 일이다. 문제는 1번 요인에 많은 항목이 묶였기 때문에 어떤 이름을 지어주어야 하나 고민이 되는데.. 각 항목의 특성을 고려해서 요인명을 만들어주어야 한다. 요인명을 어떻게 지정하느냐에 따라 연구자의 센스를 엿볼 수 있다. 내가 연구자라면, 1번 요인은 ‘관광 이동 편리성’, 2번 요인은 ‘관광지 볼거리 매력성’, 3번 요인은 ‘긍정적 감정’으로 요인명을 지어줄 것이다.
이 부분은 연구자의 주관적인 생각과 고민이 필요한 부분이므로 신중하게 결정하면 되겠다. 요인분석 자체는 어렵지 않지만, 많은 연구자들이 요인분석을 상당히 어려워하는 이유는 요인이 연구자가 희망하는 대로 좀처럼 잘 묶이지 않는다는 것, 그게 가장 힘들게 하는 부분이 아닌가 하는 생각이 든다.
마지막으로 요인분석에 대한 결과가.. 수치상으로는 전혀 문제가 없고 (오히려 잘 된 요인분석처럼 보이더라도) 전혀 이상한 항목들로 요인이 묶이는 상황이 오게 된다면 설문지 자체의 내용 타당성을 다시 점검해봐야 할 수도 있다. 그러면 기껏 받아놓은 설문 데이터를 뒤엎는 식이 되어서 이를 반길 연구자가 없겠지만.. 뭐니 뭐니 해도 데이터의 상태가 좋아야 분석 결과도 잘 나오는 것 같다.