
오늘은 SPSS에서 중복 케이스와 특이 케이스를 식별하는 방법에 대하여 알아보고자 한다. ‘주요 분석만 잘하면 됐지, 굳이 이런 부분을 알아야 해?’라고 생각할 수는 있는데 내가 직접 사용해 보니 ‘꽤나 유용하더라..’ 생각되어서 포스팅을 하게 되었다.
SPSS 분석툴은 정말이지 신기하면서 다양한 기능을 많이 제공하고 있다. 다만, 내가 이 수많은 SPSS 기능들을 다 알지도 못할뿐더러 제대로 다루지 못하는 경우가 많다는 것...(쩝) 아무튼 어떤 도구라도 잘 다룰 줄만 안다면 그만큼 분석에 있어서도 일종의 효율성을 증대시킬 수 있으니까 좋게 생각하는 편이다.
자, 먼저 분석을 위한 데이터파일을 불러와준다. 내가 만든 샘플 파일을 이용해서 분석해봐도 좋고, 바로 분석을 해야하는 경우라면 각자 코딩한 데이터 파일을 불러오면 된다. (파일 → 열기, 또는 파일 → 데이터 가져오기 기능을 이용하자)
아래 사진은 오늘 분석할 샘플 파일이다(위에 첨부했음, 필요 시 다운로드해서 연습 가능하다)

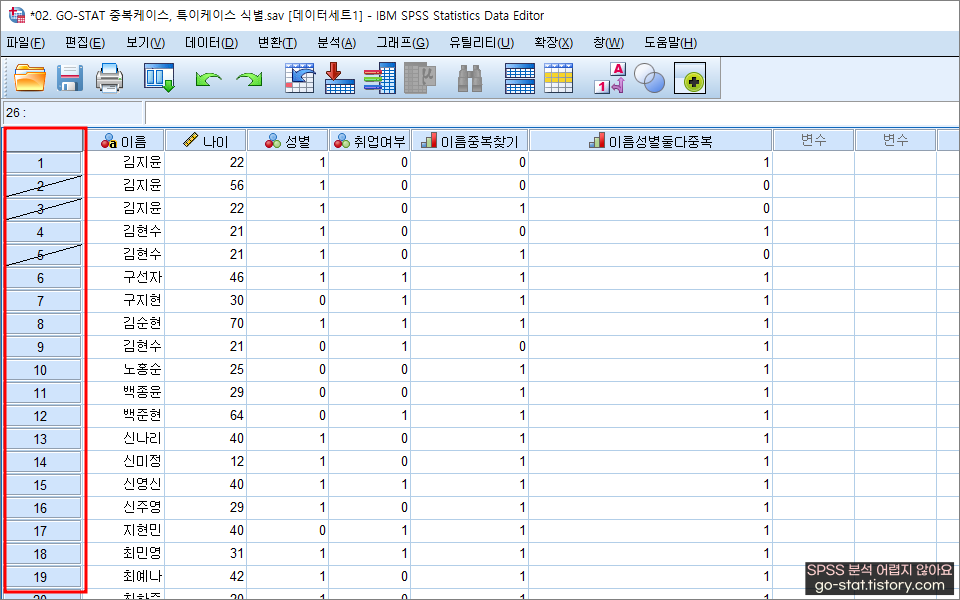
조금 숙련된 연구자라면 여기서 뭔가 이상한 낌새를 눈치채야 한다. 다그런건 아니지만 이름을 자세히 보면 중복되는 값들이 보인다.
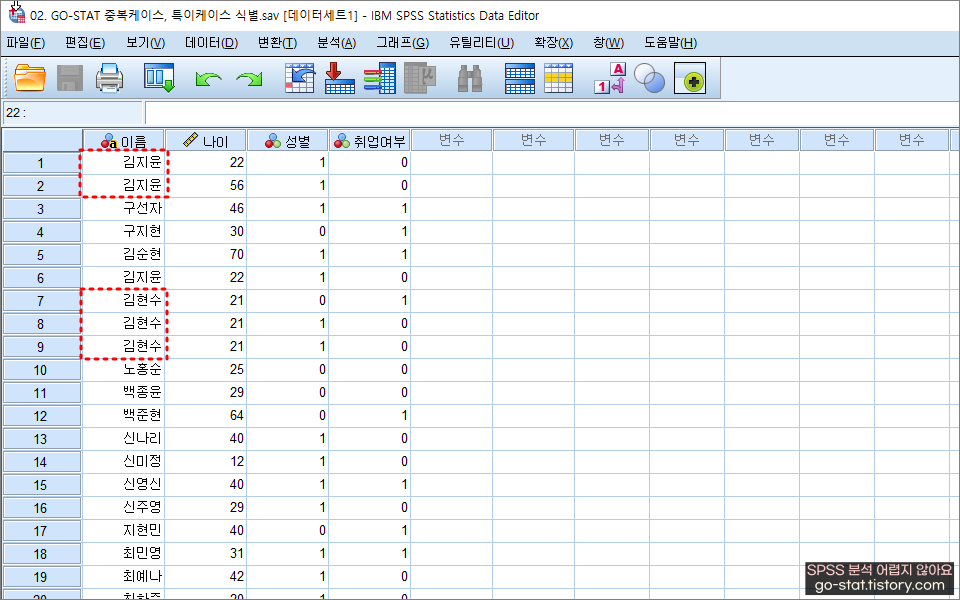
실제로 내가 설문 받은 사람들의 데이터를 보고 있다고 생각하면 이 상황이 더 잘 이해될 것이다. 서로 이름이 중복되는 응답자가 없다는 가정하에 중복값 식별하는 방법을 실습해 보자.
1. 중복값인지 알 수 있는 방법은 간단하다. 무엇을 기준으로 중복값을 처리할 것인지 먼저 정해주어야 한다. 실습을 위해 ‘이름’이란 변수를 기준으로 중복값을 식별해보고자 한다. 물론 실습이기 때문에 이름을 사용하지만, 우리나라에는 동명이인이 무척 많으므로 이름이 똑같다고 해서 무턱대고 중복값을 처리해서는 안될 것이다.
중복값 처리 기능은 ‘개인의 고유한 ID’나.. 이를테면 ‘주민등록 번호’, ‘운전면허 번호’, ‘자동차 번호’ 등의 고유한 식별인자가 있을 때 이를 기준으로 중복값을 처리하는 것이 적절하다. 꼭 기억하자! 나는 연습을 위해 이름이란 변수를 사용하지만, 여러분은 실제 상황에서 그렇게 하면 안 된다는 것을..
그럼 시작해보겠다.
바로 여기를 클릭하면 된다. 데이터 → 중복 케이스 식별(버전마다 약간 다를 수 있음) 그럼 아래와 같은 창이 하나 표시된다.
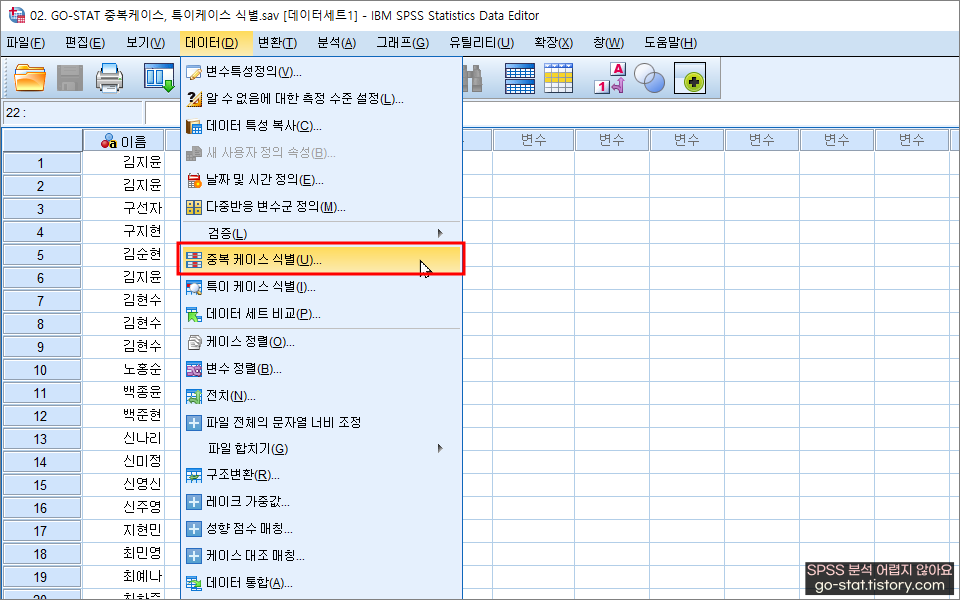
여기서 어떤 기준으로 중복 케이스를 식별하고 싶은지 넣어주면 된다. 나는 ‘이름’으로 중복 케이스를 찾길 원하기에 ‘이름’이라는 변수를 ‘매칭 케이스 정의 기준’에 넣어준다.

이내 아래와 같은 결과창이 뜨면서 SPSS에 새로운 변수가 하나 생성된 것을 확인할 수 있다. ‘보아하니 중복 케이스는 4건이구만..!’ 알 수 있는 부분이다. 참고로 여기서는 ‘각 집단의 마지막 케이스를 기준으로 중복 케이스를 식별한 경우’이다(이건 옵션에서 연구자가 지정하면 됨)
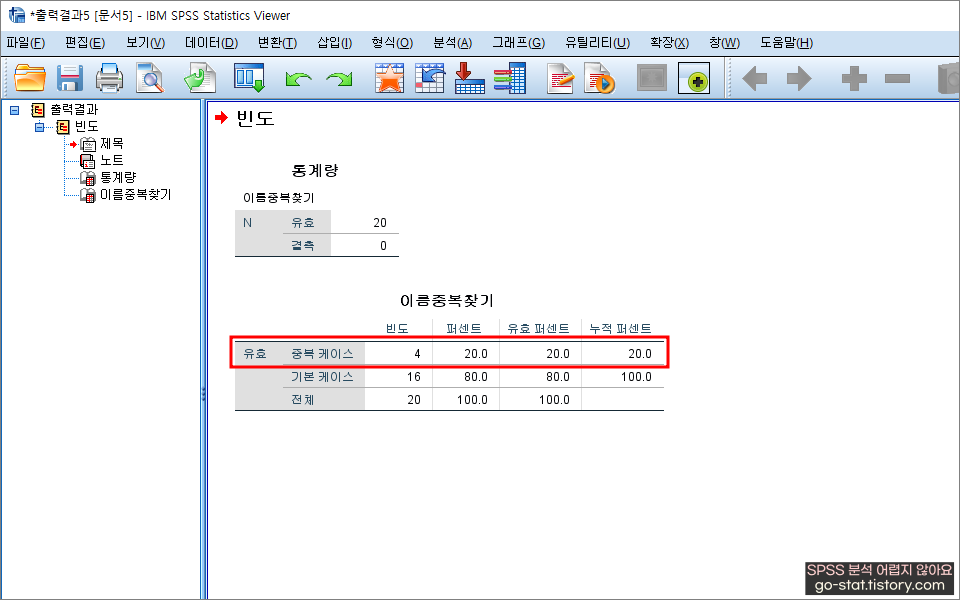
지금은 실습데이터가 20개뿐이어서 중복 케이스 식별 기능을 사용하지 않고서도 충분히 눈으로 중복 케이스를 손쉽게 알 수 있지만.. 만일 내가 분석해야 하는 데이터가 1만 개 이상이라면? 아니.. 1천 개만 된다고 생각해도 끔찍하다. 이 많은 데이터들 사이에서 중복값을 대체 어떻게 알아차릴 수 있단 말인가 ㅠㅠ
그럴 때는 이렇게 하면 된다. 일단 분석 결과창을 최소화 시켜놓고 다시 SPSS로 돌아가 보자.
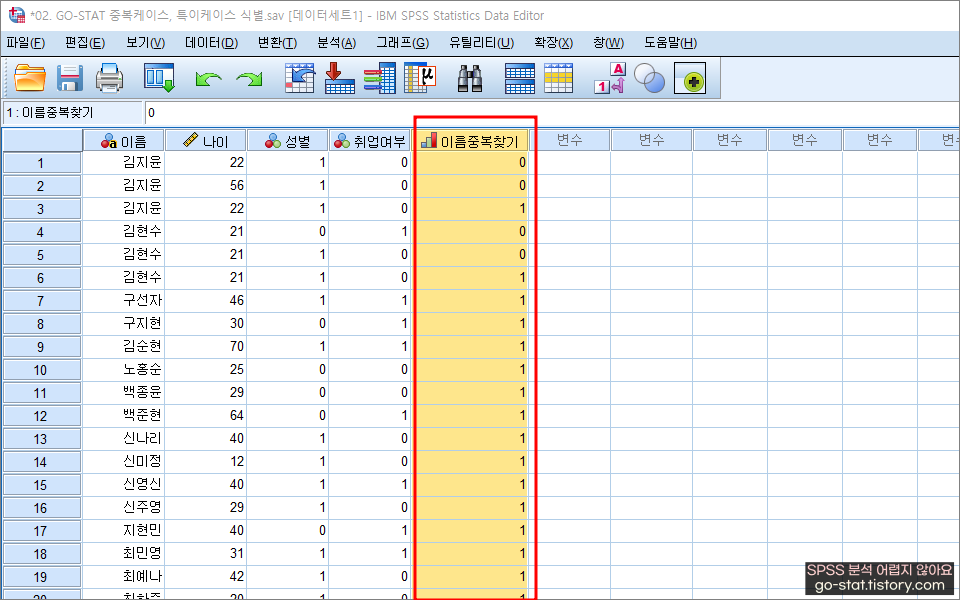
아까 중복 케이스를 식별하면서 새롭게 생겨난 변수에 주목해보자. 세상에나..! 너무나도 친절하다. 처음에 조건을 걸어준 ‘이름’을 기준으로 중복 케이스가 있는 경우에는 ‘0’이 표시되고, 그렇지 않은 값에는 ‘1’로 표시되는 것이 아닌가?
Q. 그러면 ‘이름’과 ‘성별’ 두 가지가 일치하는 경우에서 중복값을 식별할 수도 있지 않을까? 한 번 생각해볼 수 있다. 물론 SPSS에서는 두 개 이상의 변수에 입력된 값이 동일한 경우도 식별해줄 수 있다. 분석 방법은 위와 동일하게 진행하면 된다. 다만 여기서 다른 점이 있다면, 아래의 사진처럼 어떤 변수를 기준으로 중복값을 식별하고 싶은지 넣어주기만 하면 된다. 실습을 위해 ‘이름’과 ‘성별’을 둘 다 넣어주고 확인을 눌러준다.
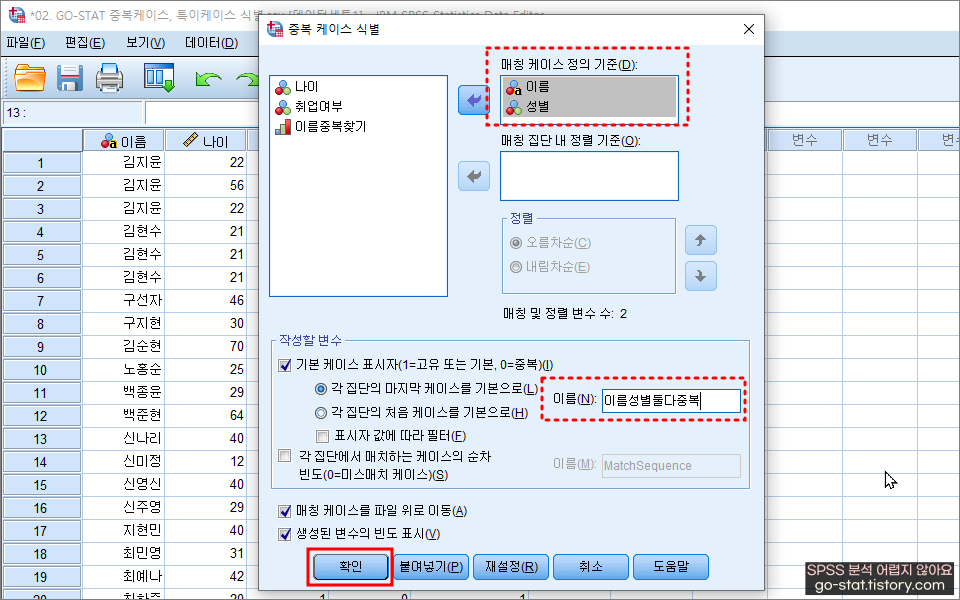
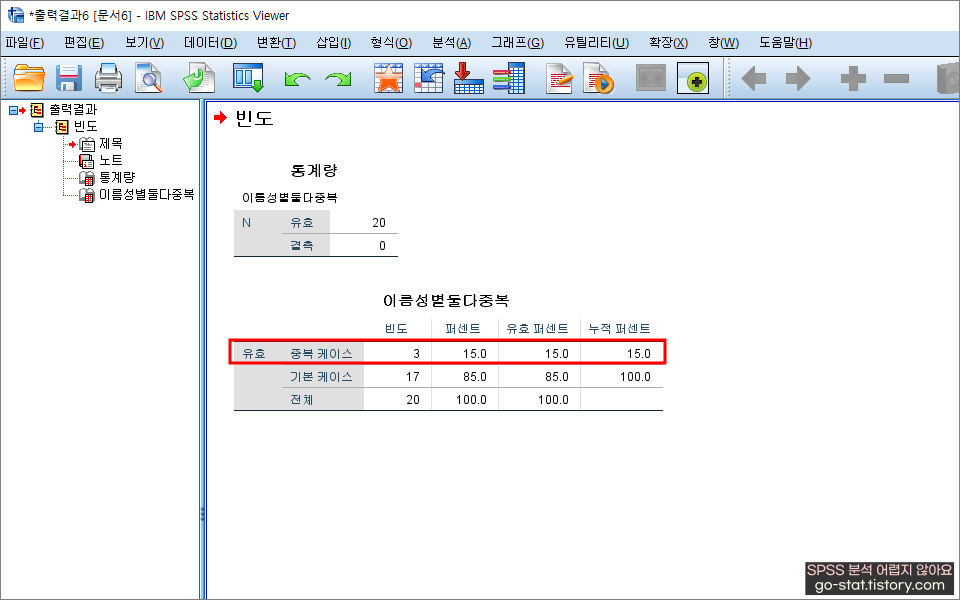
그러면 아까와는 다르게, 이름과 성별 모두 (이 두가지가 일치하는) 응답자의 데이터가 몇 개인지 알려준다. 총 3건으로 나오는군 ^^
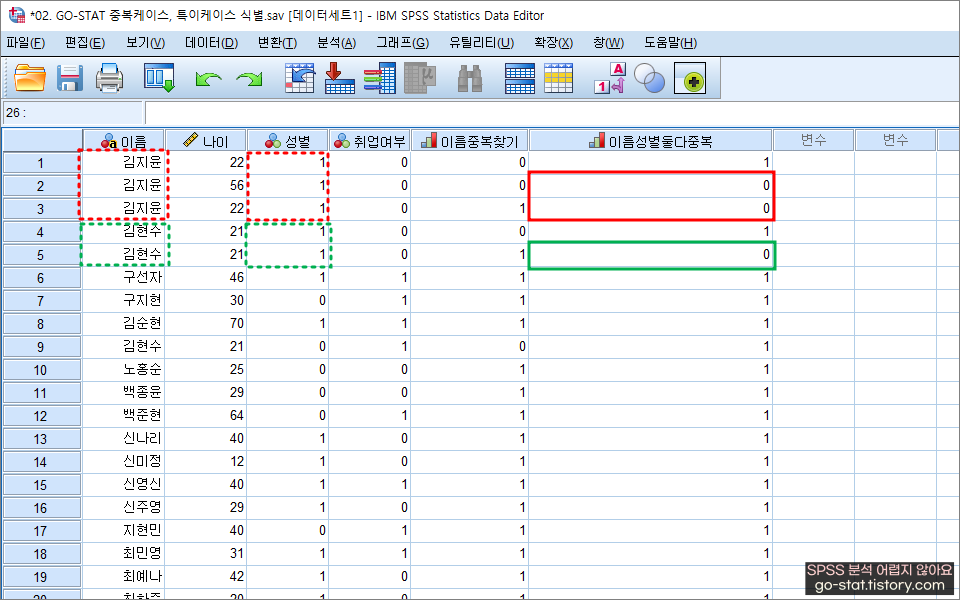
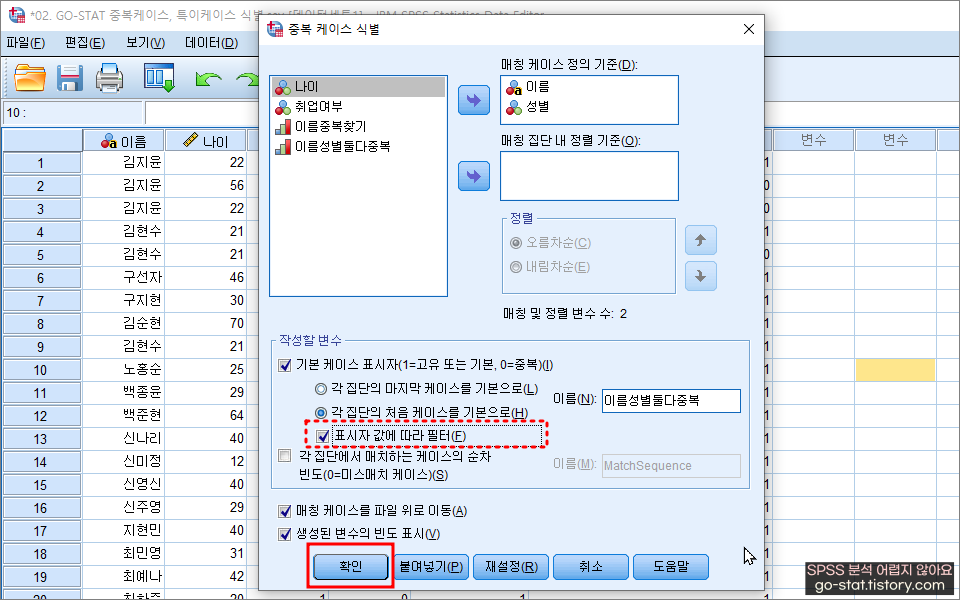
참고로, 중복값을 필터링하고 싶으면 이렇게 하면 된다. 이전 화면에서 ‘표시자 값에 따라 필터’를 클릭해 주자. 이렇게 하면 보다 직관적으로 어떤 값들이 중복 케이스에 속하는지 확인할 수 있다. 참고로 나는 ‘각 집단의 처음 케이스를 기본으로’에 설정하였다. 이 부분은 연구자가 보고 각 집단의 마지막 케이스를 기본으로 할 것인지, 처음 케이스를 기본으로 할 것인지는 정하면 되는 부분임을 기억하고 중복값을 필터링할 수 있으면 된다.
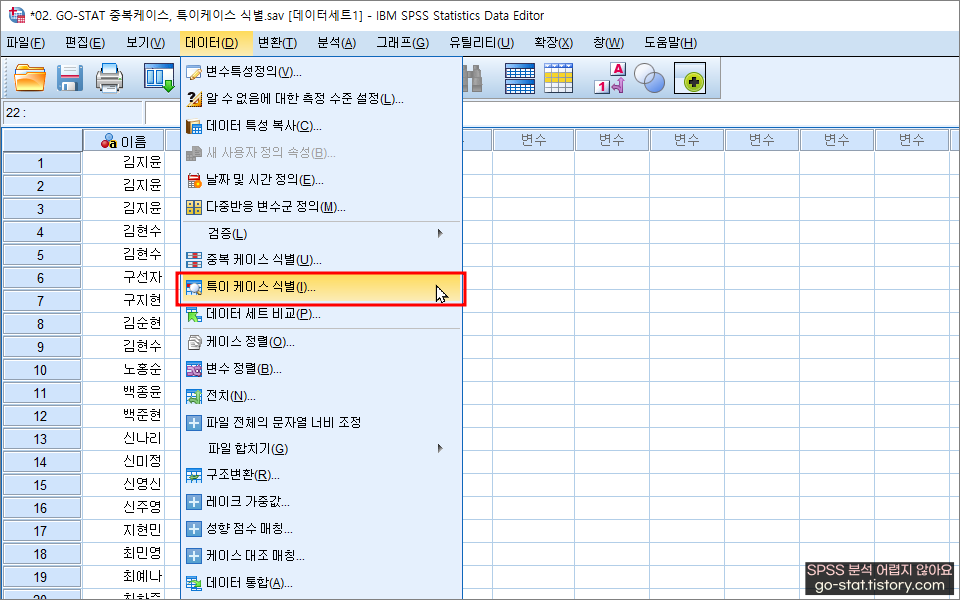
2. 그러면 데이터의 특이 케이스는?
이렇게 알 수 있다. 대상이 되는 분석변수를 투입하고(하나만 넣어도 되고, 전부 다 넣어도 상관없음. 분석의 대상을 자율껏 보고 지정하면 됨!) 확인을 눌러주면 된다.
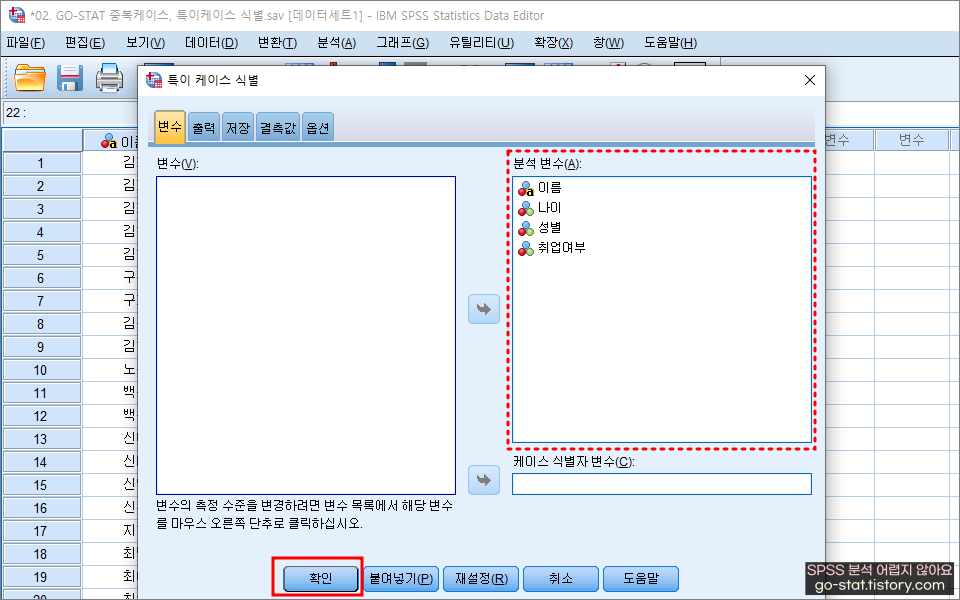
나는 일단 모든 변수를 넣어봤는데 다행이 특이 케이스는 없다고 나온다.
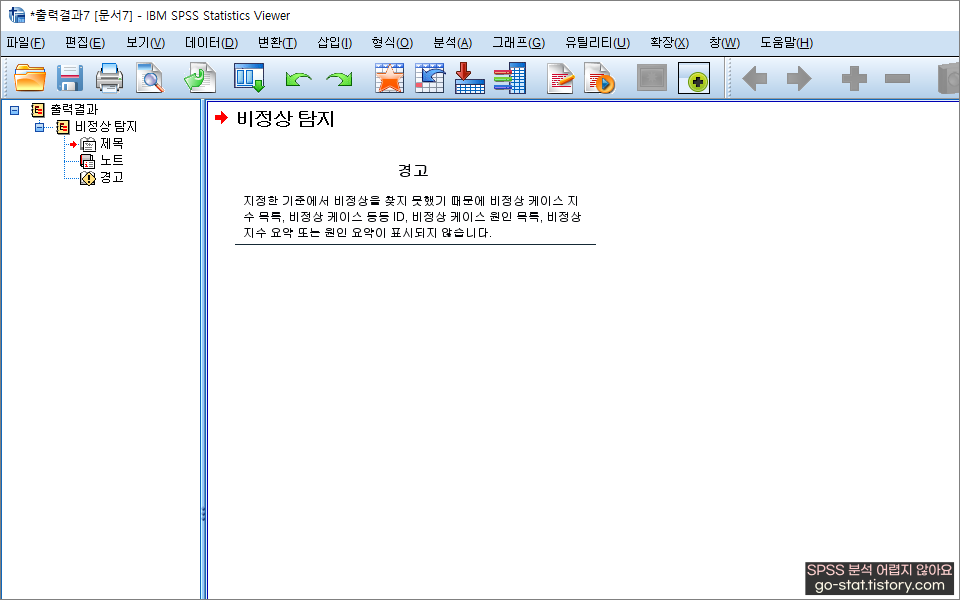
특이 케이스 선별하는 기준을 정확히는 모르겠지만, 경험상 1천 개 이상의 데이터를 가지고 특이 케이스를 분석하면 몇 개씩은 특이 케이스에 걸리는 경험이 있기는 하다. 아무튼, 비정상 탐지에서 이상 없으므로 특이 케이스 식별은 여기에서 마치려고 한다.
참고로 다른 실습 데이터에서 특이 케이스가 발생하면 아래의 화면과 같이 분석 결과가 뜬다. 참고용으로 알아두자.
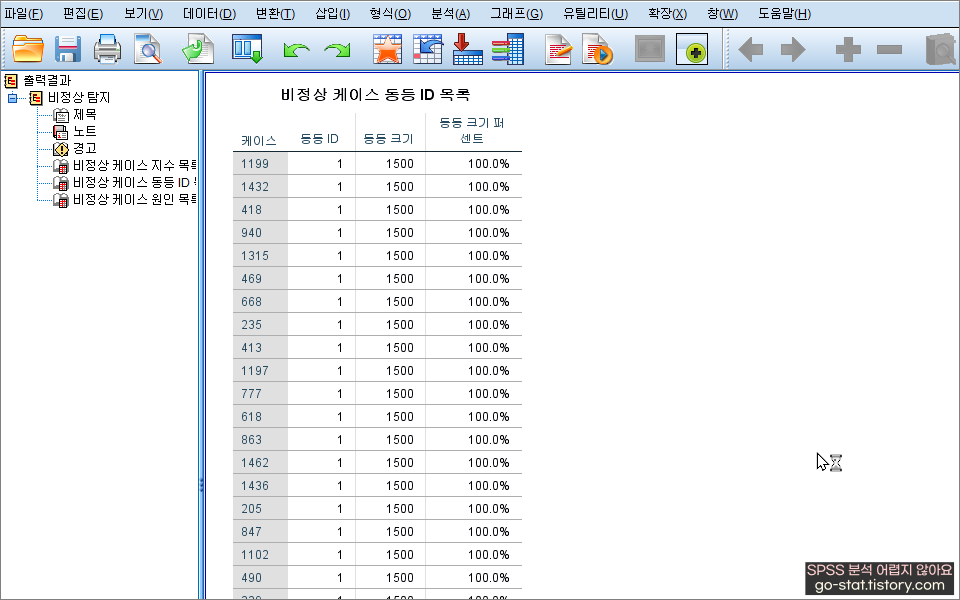
그런데 분석을 하다보면 특이한 경우가 워낙 많다 보니, 특이 케이스 기능만 이용해서는 특이 케이스를 전부 식별하기 어렵다. 어떻게 보면 오늘 실습한 ‘중복 케이스 식별하기’도 특이 케이스를 식별하는 과정 중 하나라고 생각된다.
이상으로 포스팅을 마치려 한다. 내 포스팅이 SPSS를 연습하는 많은 사용자들에게 도움이 되면 좋겠다.